CMU 15-618 (Spring 2016) Project
Hardware Performance Measurement of Different HashMap Implementations in Golang
by:
Hechao Li (hechaol)
Ahmet Emre Unal (ahmetemu)

Final (May 9th, 2016)
Tested Implementations
In total, we have tested 5 different concurrent Go hashmap implementations. Ranging from coarse-grained locked to lock-free implementations, these maps are (and referred on the rest of the report as):
'Lock' Map (Coarse-Grained Lock)
This is the simplest implementation. The author of this hashmap simply threw around a single lock around the entire table. When a thread issued any of the Get()/Put()/Remove() functions, the thread locks down the entire table, essentially making it sequential.
'RWLock' Map (Finer-Than-Coarse-Grained Lock)
This implementation is similar to Lock Map but uses a Read/Write lock instead of a regular lock. Get() functions use the Read lock, while Put() and Remove() use the Write lock.
'Parallel' Map (Single Read/Write Thread)
This implementation uses a single control thread approach. A single goroutine is responsible for reading from and writing to the map, while other goroutines issue Get()/Put()/Remove() functions by putting them on a channel, which the single map control goroutine consumes. As a result, this implementation is actually entirely lock-free and uses no atomic operations (other than [possibly] Golang's channel internals).
This implementation is available here.
'Concurrent' Map (Fine-Grained Lock)
This implementation is a port of Java's ConcurrentHashMap to Golang. This implemenation has 3 layers:

- ConcurrentHashMap, which constitutes the single whole hash map object. It contains multiple:
- Segment(s), each of which constitutes a mini hash map object. Each contain mutliple:
- HashEntry(s), each of which constitutes an element of the hash map.
When accessing any HashEntry for an operation other than a Get(), the whole segment gets locked. Get() operations do not cause anything to be locked; it gets the value atomically. Put() and Remove() operations, however, causes the whole segment to be locked. 'HashEntry's are immutable, thus a Remove() causes all previous 'HashEntry's to be copied and the new copy points to the next 'HashEntry' of the removed entry.
This implementation is available here.
'Gotomic' Map (Lock-Free)
This implemenation is based on the work of Ori Shalev and Nir Shavit, both of Tel-Aviv University. Their approach is outlined in this document, titled 'Split-Ordered Lists: Lock-Free Extensible Hash Tables'. This hashmap is backed by the non-blocking linked list work of Timothy L. Harris of the University of Cambridge. His approach is outlined in this document, titled 'A Pragmatic Implementation of Non-Blocking Linked-Lists'.
The core structure of the algorithm is recursive split-ordering, a way of ordering elements in a linked list so that they can be repeatedly "split" using a single compare-and-swap operation; "Extensibility is derived by 'moving the buckets among the items' rather than 'the items among the buckets'."
The implemenation has 2 layers: An expanding array of pointers into the linked list and said linked list of nodes containing the key-value pairs:
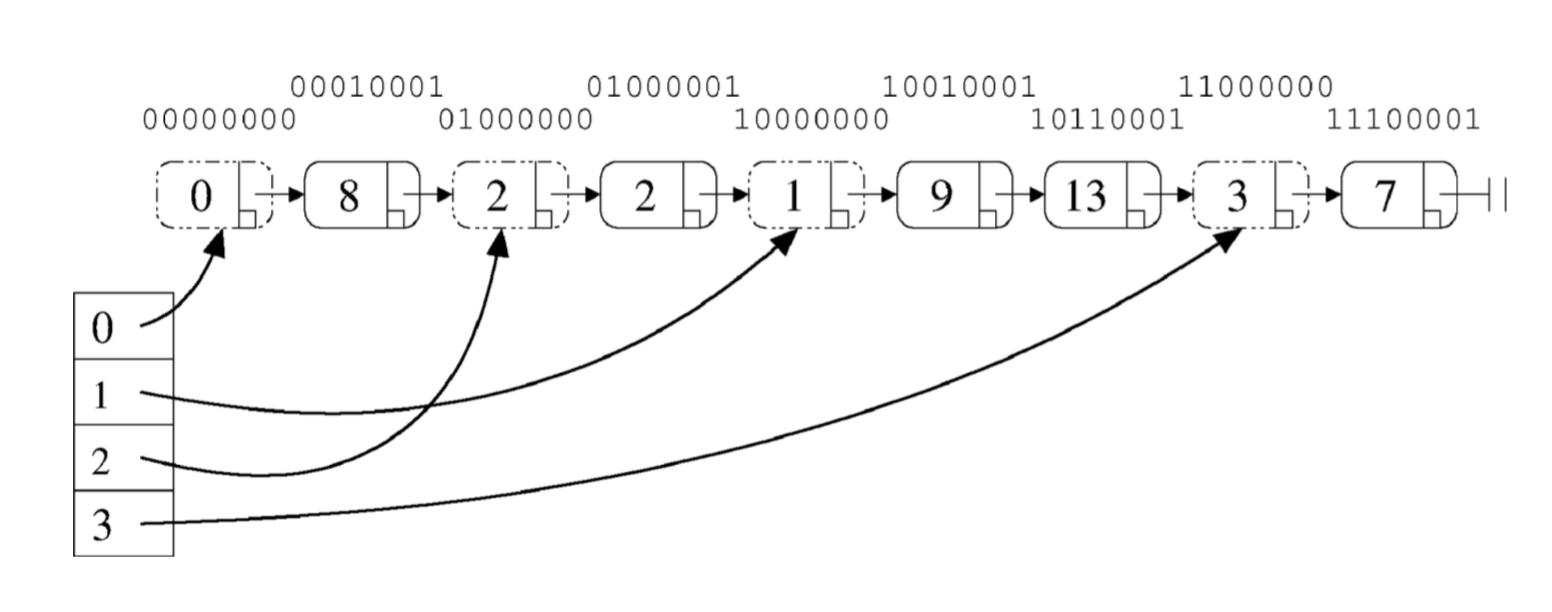 The array entries are the logical 'buckets', typical of most hash tables. Any item in the hash table can be reached by traversing down the list from its head, while the bucket pointers provide shortcuts into the list in order to minimize the search cost per item. Get()/Put()/Remove() operations all use atomic operations to perform the necessary changes in the map. Put() operation may add buckets to the map. Remove() operation only removes the element in the list.
The array entries are the logical 'buckets', typical of most hash tables. Any item in the hash table can be reached by traversing down the list from its head, while the bucket pointers provide shortcuts into the list in order to minimize the search cost per item. Get()/Put()/Remove() operations all use atomic operations to perform the necessary changes in the map. Put() operation may add buckets to the map. Remove() operation only removes the element in the list.
Test Environment
We used a machine with the following specifications for our test environment:
- Machine: Dell OptiPlex 790
- OS: Lubuntu Linux x86_64, kernel version 4.4.0-22-generic
- Processor: Intel Core i7-2600 CPU @ 3.40GHz (4 cores, 2 execution contexts per core)
- Memory: 2x 4 GB DDR3 1333 Mhz
- Storage: Seagate ST31000524AS 1TB
We used the perf tool, available on Linux, to make the measurements.
Test Mechanism
The testing mechanism worked as follows:
- The test application is ran with perf collecting data in the background.
- Depending on the input, the test application created a hashmap instance.
- The test application spawned one goroutine per execution context (NumCores) (which is 8 threads in total for our testing machine) and allowed goroutines to spawn that many threads (essentially mapping one goroutine per thread).
- The test application ran the simulation scenario.
- For scenarios that require more than the number of execution units of goroutines, each thread handled multiple goroutines (as is common with goroutines.
Test Scenarios
We identified many test scenarios and ran all of them. The following are our test scenarios, along with their ID:
- Lots of concurrent writes to a single map by NumCores threads/goroutines, uniformly random keys
- Lots of concurrent writes to and few concurrent reads from a single map by NumCores threads/goroutines, uniformly random keys
- Lots of concurrent writes to and lots of concurrent reads from a single map by NumCores threads/goroutines, uniformly random keys
- Lots of concurrent reads from a single map by NumCores threads/goroutines, uniformly random keys
- Scenarios 1-4 with a very large data set (to force swap space use), uniformly random keys (These tests have been cancelled)
- Scenario 1 with a very large data set (to force swap space use)
- Scenario 2 with a very large data set (to force swap space use)
- Scenario 3 with a very large data set (to force swap space use)
- Scenario 4 with a very large data set (to force swap space use)
- Scenarios 1-4 with normally distributed random keys
- Scenario 1 with normally distributed random keys
- Scenario 2 with normally distributed random keys
- Scenario 3 with normally distributed random keys
- Scenario 4 with normally distributed random keys
- Scenarios 1-4 with sequential keys
- Scenario 1 with sequential keys
- Scenario 2 with sequential keys
- Scenario 3 with sequential keys
- Scenario 4 with sequential keys
- 100 concurrent writers, 10 concurrent readers writing to and reading from a single map
- 10 concurrent writers, 100 concurrent readers writing to and reading from a single map
- 1 concurrent writers, 100 concurrent readers writing to and reading from a single map
- Fill the map, delete all, fill again, etc. (to test the resize behavior)
Test Results
Since there were a lot of test scenarios, which resulted in a lot of data being gathered and many charts being generated, they are not included on the website. All the generated data and charts, broken down by test scenario and map implemenation is available here.
Unfortunately, due to the infeasible running time of the tests 5.x (single one running for multiple days), those tests have been cancelled and omitted from the results.
Discussion
From the data we gathered, we can see that gotomic map always has the highest number of cache misses but also usually has the shortest running time. The reason for which is the complexity of data structures that gotomic uses; it has more overhead than other map implemenations. But since it is totally lock-free, there is no overhead of lock acquire or release, which makes it the fastest one for concurrent access.
In contrast, the parallel map is usually the slowest one. It is internally sequential — it does all the operations (Get()/Put()/Remove()) through only one thread, completely sequentially. However, along with having the longest run time, this structure allows it to have the lowest cache miss rate among all the other map types. Some of the reasons for the low cache miss rate is the implementation being quite simple and lightweight, as well as only a single thread (thus [potentially] a single execution context) using it, which results in lower communication among cores and a lower rate of invalidations of map data. This result leads us to believe that if speed is not as important as memory usage, or if memory access uses a huge amount of energy compared to cache access, this implemenation could be a viable choice.
Surprisingly, the performance of the RWLock map is almost the same as using a coarse-grained locked map. In some test cases, RWLock is even slower than the coarse-grained locked map. Only in scenarios in which readers are many more than writers, we can see an obvious speedup. Since write lock is an exclusive lock, once there are lots of write operations, RWLock becomes no better than a regular coarse-grained lock. Additionally, due to the overhead of a RWLock, it becomes even slower than coarse-grained locks in write-intensive tests.
Concurrent hashmap is comparable in performance to the gotomic hashmap. In concurrent read/write tests (Tests 8-10), Concurrent hashmap is much faster. Concurrent hashmap only uses a lock in Put() and Remove() operations (which only locks a segment, not the entire map). For Get() it is entirely lock-free. This fact underlines the fact that lock-free implementations do not always outperform fine-grained locks.
Checkpoint (April 19th, 2016)
So far, we have identified several scenarios to write test cases for and written tests for most of them. Scenarios include:
- Lots of writers, lots of readers
- Lots of writers, few readers
- Few readers, lots of writers
- Writing a lot, then deleting a lot (in order to observe resize behavior)
- Writing and reading so much that page swapping occurs
- And variations of the above ones, with differing access patterns (accessing keys uniformly randomly, some of them more than the others, etc.)
As we are observing several different Go Map implementations, we were pleased to see a wide gaps in performance between different implementations. A link to the latest benchmarks (created by Go's benchmarking tools from its testing suite) is here.
Goals
Since our original proposal was about examining low-level differences in behavior of these implementations (cache behavior, for example), we will be proceeding with examining these test conditions with tools such as perf and Intel VTune. This brings us to an important issue we currently are facing:
Issues
Intel VTune is available on the Windows and Linux platforms. Perf tool is available only on the Linux platform. The extensive testing required by these scenarios make one team member's Linux computer unsuitable for testing. The other team member's Mac is unsuitable due to platform difference.
Using VMs are, unfortunately, out of the question (as far as we've been able to understand), since the virtual processors exposed by the VMM abstracts away performance counters in the chips themselves.
We currently require a Linux machine to run tests on, in a consistent environment, which may last for couple of hours at a time. Tests such as the ones that incur memory page swapping are unsuitable to run on Gates machines or Latedays. We have contacted Prof. Kayvon with this requirement and are awaiting further instructions.
Unknowns
The 3rd party map implementations are not extensively studied and might include bugs and/or code that results in sub-par performance. We are planning on studying these libraries in further detail.
Next steps
- Test cases on large set of keys and values. For example, we can test the case where the memory used by the map cannot fit into memory (> 16 GB or so). We then can know the performance when these maps need to use swap file.
- Go’s internal benchmark package has limited functionality. We need to use other performance measuring tools such as perf and Intel VTune to test the cache behavior.
- Read the codes of these lock-free version maps and understand their principles in order to do better comparison and perhaps even improve their performance. Read related papers such as the one that gotomic is based on.
- Plot graphs to show the performance comparison in each test case.
Proposal (Mar 31st, 2016)
Our project proposal can be found here.